读写流程
写流程
具体过程如下:
- Client 调用 DistributedFileSystem 对象的 create 方法,创建一个文件输出流(FSDataOutputStream)对象;
- 通过 DistributedFileSystem 对象与集群的 NameNode 进行一次 RPC 远程调用,在 HDFS 的 Namespace 中创建一个文件条目(Entry),此时该条目没有任何的 Block,NameNode 会返回该数据每个块需要拷贝的 DataNode 地址信息;
- 通过 FSDataOutputStream 对象,开始向 DataNode 写入数据,数据首先被写入 FSDataOutputStream 对象内部的数据队列中,数据队列由 DataStreamer 使用,它通过选择合适的 DataNode 列表来存储副本,从而要求 NameNode 分配新的 block;
- DataStreamer 将数据包以流式传输的方式传输到分配的第一个 DataNode 中,该数据流将数据包存储到第一个 DataNode 中并将其转发到第二个 DataNode 中,接着第二个 DataNode 节点会将数据包转发到第三个 DataNode 节点;
- DataNode 确认数据传输完成,最后由第一个 DataNode 通知 client 数据写入成功;
- 完成向文件写入数据,Client 在文件输出流(FSDataOutputStream)对象上调用 close 方法,完成文件写入;
- 调用 DistributedFileSystem 对象的 complete 方法,通知 NameNode 文件写入成功,NameNode 会将相关结果记录到 editlog 中。
**读流程**
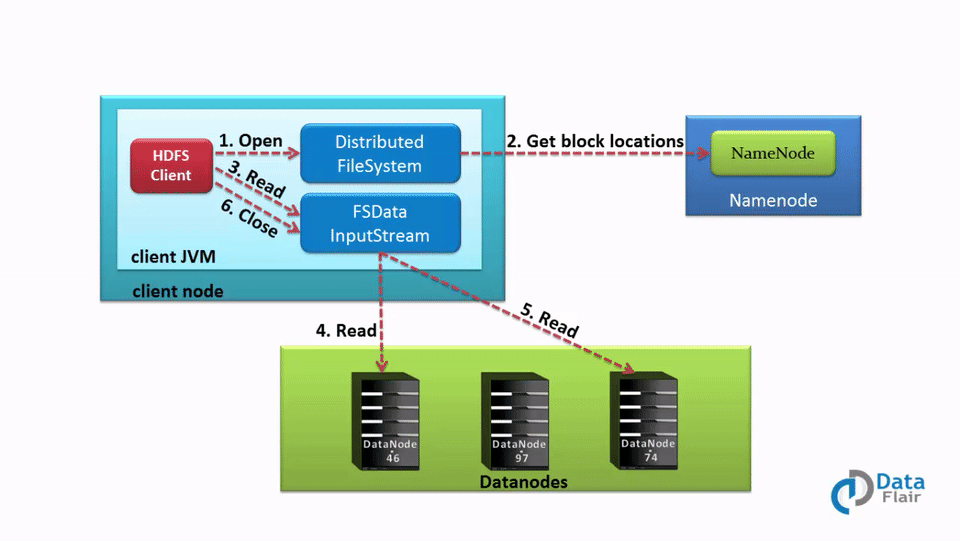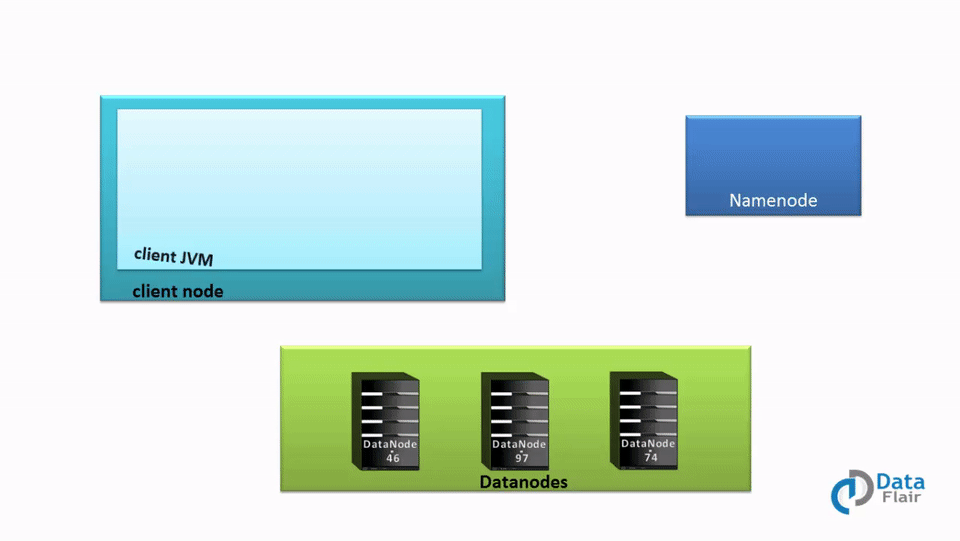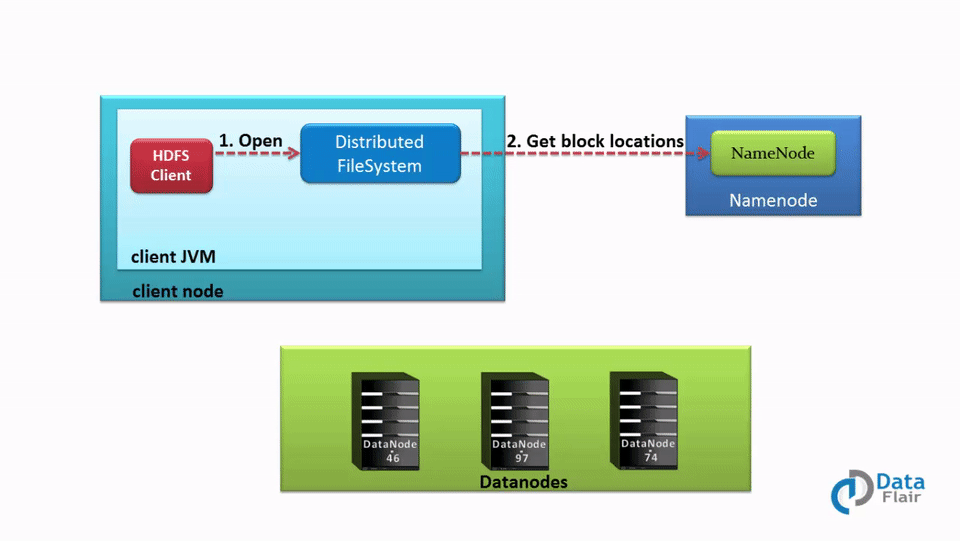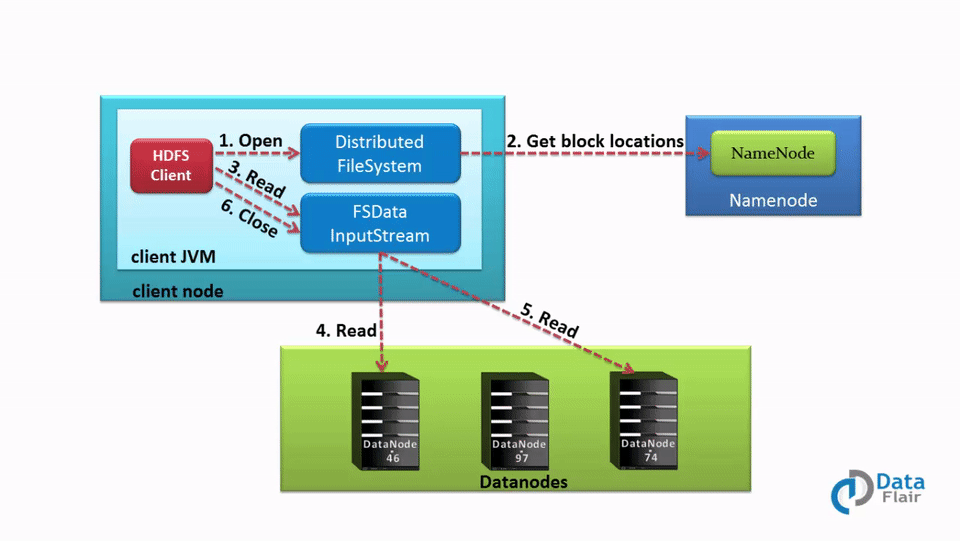
具体过程:
- Client 通过 DistributedFileSystem 对象与集群的 NameNode 进行一次 RPC 远程调用,获取文件 block 位置信息;
- NameNode 返回存储的每个块的 DataNode 列表;
- Client 将连接到列表中最近的 DataNode;
- Client 开始从 DataNode 并行读取数据;
- 一旦 Client 获得了所有必须的 block,它就会将这些 block 组合起来形成一个文件。
在处理 Client 的读取请求时,HDFS 会利用机架感知选举最接近 Client 位置的副本,这将会减少读取延迟和带宽消耗。
写流程中备份三,其中一个写失败了怎么办?
只要成功写入的节点数量达到dfs.replication.min(默认为1),那么就任务是写成功的。然后NameNode会通过异步的方式将block复制到其他节点,使数据副本达到dfs.replication参数配置的个数
HDFS HA 启动流程
①开启zookeeper服务
1 | zkServer.sh start |
②开启`journalNode`守护进程(在`journal`协议指定的节点上执行)[ˈdʒɜːnl]
1 | hadoop-daemon.sh start journalnode |
③开启namenode守护进程(在nn1和nn2执行)
1 | hadoop-daemon.sh start namenode |
④开启datanode守护进程
1 | hadoop-daemons.sh start datanode |
⑤开启zkfc守护进程
1 | hadoop-daemon.sh --script $HADOOP_PREFIX/bin/hdfs start zkfc |
HDFS 存储类型
HDFS支持如下4种存储类型:
- DISK:表示普通磁盘(机械磁盘)
- SSD:表示固态硬盘
- RAM_DISK:表示内存硬盘,参考虚拟内存盘,说白了就是内存
- ARCHIVE:这个并不是特指某种存储介质,而是为了满足高密度存储而定义的一种存储类型,一般对于归档的、访问不怎么频繁的数据可以以 ARCHIVE 的形式存储。
以上四种的存储类型的存取的速度大小为:RAM_DISK->SSD->DISK->ARCHIVE。但是单bit存储成本由高到低
那么我们在配置DataNode的存储路径的时候,我们可以分别为上面四种存储类型配置存储位置,如下图:
1 | <property> |
上面配置的DataNode的多个存储位置由逗号隔开,每一个存储位置由存储类型和存储物理路径组成。HDFS通过该配置感知底层存储的位置和类型
HDFS是否有异步访问模式?
在现有HDFS的RPC调用方式上,采用的基本是blocking call的形式,也就是阻塞式的调用方式.阻塞方式的一个明显的缺点是它的请求过程是同步的,也就是说,客户端必须等待当前请求结果的返回,才能接着发送下一次请求.如果此客户端打算在一个线程中发送大量请求的话,阻塞式的RPC调用将会非常耗时.
但是如果为了每一次请求调用而专门单独开一个线程的话,系统资源将会被大幅度的使用,显然这也不是一个好的解决的办法.那么有没有什么好的办法呢,在HDFS中是否存在有异步模式的RPC请求接口呢本文我们就来聊聊HDFS的异步访问模式.
- HDFS异步访问模式
老实说,在目前Hadoop的发布版本中,确实还不存在HDFS异步访问的模式,但是这并不代表社区没有在关注这方面的问题.在许多特殊的场景下,HDFS的异步访问模式还是有它独到的用处的.社区在JIRA HDFS-9924([umbrella] Nonblocking HDFS Access)上对此功能特性进行了实现.在本文中,我们姑且取名”HDFS异步访问模式”为AsyncDistributedFileSystem,与DistributedFileSystem相对应.
- HDFS异步访问模式原理
在HDFS异步访问模式的设计文档中,给出了新的异步的RPC调用模式,采用了Future-Get的异步调用模式,以FileSystem的rename方法
- 客户端异步请求的控制
在前面HDFS异步访问模式的过程中,有一点必须格外引起注意:客户端异步请求的控制.客户端应有异步请求数的限制,以此防止客户端利用大量的异步请求冲垮服务端.如果超过了此限制阈值,客户端的请求将会处于阻塞状态.这点必须要引起足够重视,否则客户端随随便便发起的请求将会摧毁NameNode.
- HDFS异步访问模式的优化点
第一, 保证异步请求的有序性.在某些场景下,我们需要保证异步请求能够按照请求发起的时间,顺序执行.
第二, 客户端对HDFS读写异步请求的支持.
- 总结
HDFS Async调用模式的出现将会带给用户更灵活的RPC请求方式的选择,但是可能考虑到此种方式对比之前的方式而言,改动较大,目前这些异步调用相关的方法许多是打上了@Unstable标记的.HDFS异步调用的方式同样可以很好的运用在单元测试上.鉴于此特性是还暂未发布,大家可以根据自己的需要,进行部分的合入.
调整数据块大小会有什么影响?
Hadoop 1.x 中, 默认的数据块大小是 64M
Hadoop 2.x 中, 默认的数据块大小是 128M
在HDFS中,数据块不宜设置的过大,也不适宜设置的过小。主要是从 减少寻址时间和MR任务并行方面去考虑
- 为什么HDFS中块(block)不能设置太大,也不能设置太小?
- 如果块设置过大,
一方面,从磁盘传输数据的时间会明显大于寻址时间,导致程序在处理这块数据时,变得非常慢;
另一方面,mapreduce中的map任务通常一次只处理一个块中的数据,如果块过大运行速度也会很慢。
2. 如果块设置过小,
一方面存放大量小文件会占用NameNode中大量内存来存储元数据,而NameNode的内存是有限的,不可取;
另一方面文件块过小,寻址时间增大,导致程序一直在找block的开始位置。
因而,块适当设置大一些,减少寻址时间,那么传输一个由多个块组成的文件的时间主要取决于磁盘的传输速率。
- HDFS中块(block)的大小为什么设置为128M?
- HDFS中平均寻址时间大概为10ms;
2. 经过前人的大量测试发现,寻址时间为传输时间的1%时,为最佳状态;
所以最佳传输时间为10ms/0.01=1000ms=1s
3. 目前磁盘的传输速率普遍为100MB/s;
计算出最佳block大小:100MB/s x 1s = 100MB
所以我们设定block大小为128MB。
实际在工业生产中,磁盘传输速率为200MB/s时,一般设定block大小为256MB,磁盘传输速率为400MB/s时,一般设定block大小为512MB
以后随着新一代磁盘驱动器传输速率的提升,块的大小将被设置得更大

